
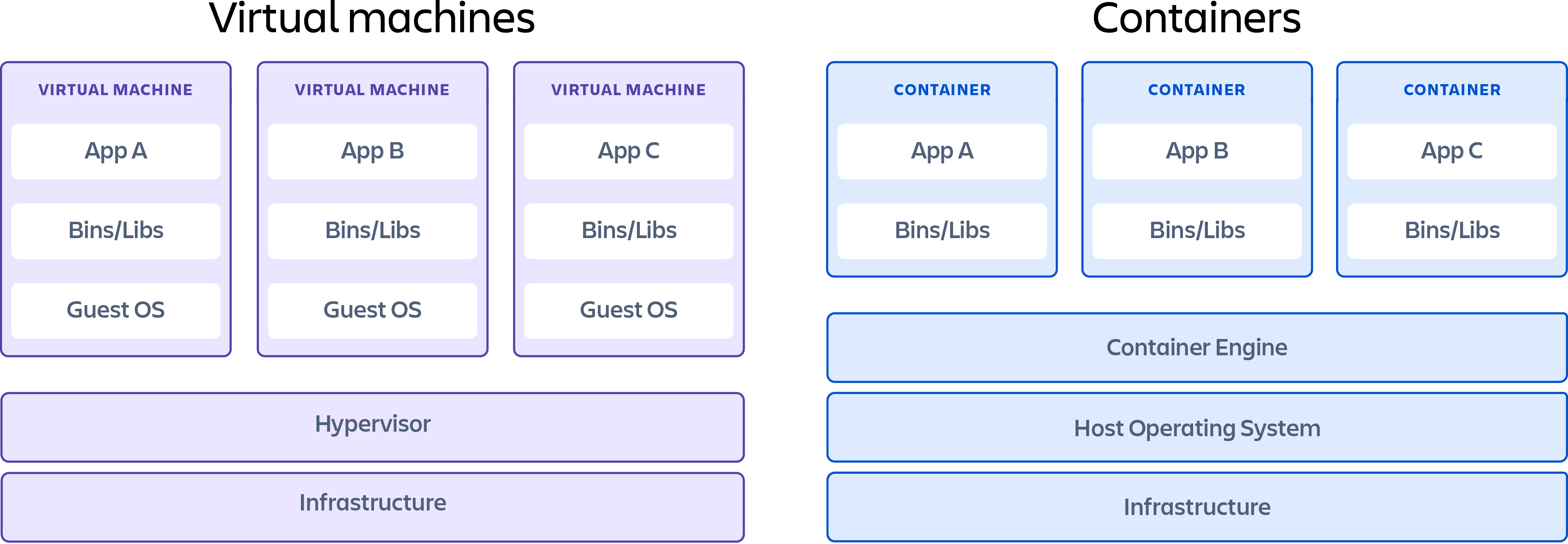
Контейнеры vs. виртуальные машины
В первую очередь, не следует путать контейнеризацию и виртуализацию. Виртуализация — это процесс, в котором отдельный ресурс системы, такой как ОЗУ, ЦП, диск или сеть, может быть «виртуализирован» и представлен в виде нескольких ресурсов. Ключевое различие между контейнерами и виртуальными машинами заключается в том, что виртуальные машины виртуализируют всю машину вплоть до аппаратных уровней, а контейнеры изолируют только программные уровни выше уровня операционной системы.
Контейнеризация
Контейнеры — это технология, которая позволяет нам запускать процесс в независимой среде с другими процессами на одном компьютере. Для этого создаются легковесные пакеты ПО, которые содержат все зависимости, необходимые для выполнения содержащегося в них программного приложения. Эти зависимости включают в себя такие вещи, как системные библиотеки, внешние пакеты стороннего кода и другие приложения уровня операционной системы. Зависимости, включенные в контейнер, работают на уровнях стека, которые выше уровня операционной системы.
Так как же контейнер это делает? Для этого контейнер создается на основе нескольких функций ядра Linux, двумя основными из которых являются «namespaces» (пространства имен) и «cgroups» (группы управления).
Пространства имен Linux
Пространства имен — это функция ядра Linux, которая разделяет ресурсы ядра таким образом, что один набор процессов видит один набор ресурсов, а другой набор процессов видит другой набор ресурсов, таким образом выполняется изоляция процессов.
Пространства имен Linux бывают разных типов:
- Пользовательское пространство имен (user namespace) имеет собственный набор идентификаторов пользователей и групп для назначения процессам. В частности, это означает, что процесс может иметь привилегии root в своем пространстве имен пользователя, не имея его в других пространствах имен пользователей.
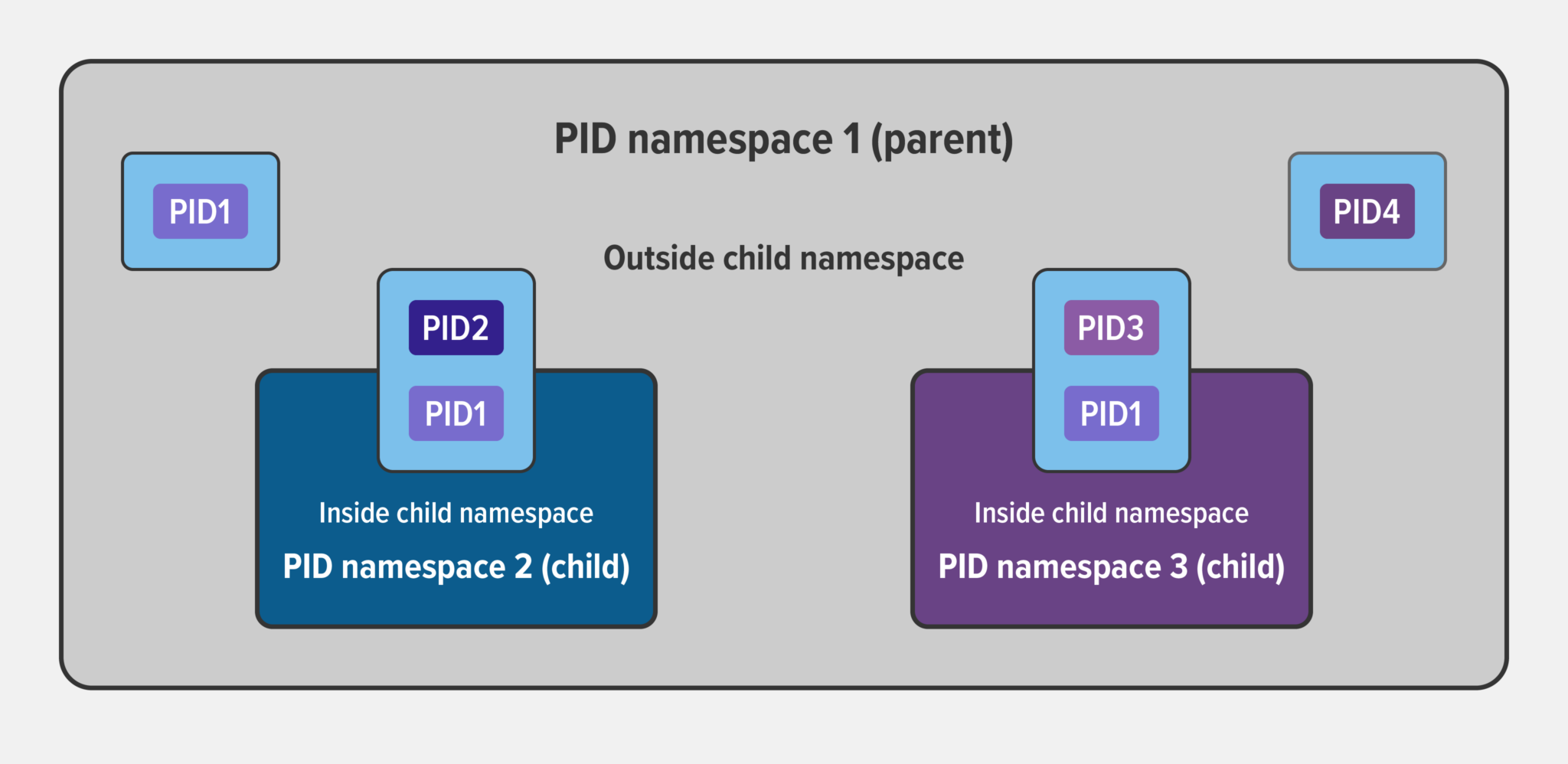
- Пространство имен идентификатора процесса (PID namespace) назначает набор идентификаторов PID процессам, которые независимы от набора идентификаторов PID в других пространствах имен. Первый процесс, созданный в новом пространстве имен, имеет PID 1, а дочерним процессам назначаются последующие PID.
- Пространство сетевых имен (network namespace) имеет независимый сетевой стек: собственную таблицу маршрутизации, набор IP-адресов, список сокетов, таблицу отслеживания соединений, брандмауэр и другие сетевые ресурсы.
- Пространство имен монтирования (mount namespace) имеет независимый список точек монтирования, видимых процессам в пространстве имен. Это означает, что вы можете монтировать и размонтировать файловые системы в пространстве имен монтирования, не затрагивая файловую систему хоста.
- Пространство имен межпроцессного взаимодействия (IPC namespace) имеет свои собственные ресурсы IPC, например очереди сообщений POSIX.
- Пространство имен UNIX с разделением времени (UTS namespace) позволяет одной системе иметь разные имена хоста и домена для разных процессов.
Пример изоляции процессов по PID родительских и дочерних неймспейсов:
Создать пространство имен Linux довольно просто: мы используем команду unshare, которая создаст отдельный процесс и заассайнит процесс bash на него.
sudo unshare --fork --pid --mount-proc bashФактически, эта команда делает то же самое, что на примере рантайма docker делает:
docker exec -it <image> /bin/bashТеперь если запустить ps aux в этом неймспейсе, то мы увидим только 2 процесса:
root@namespace:~# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 23104 4852 pts/0 S 21:54 0:00 bash
root 12 0.0 0.0 37800 3228 pts/0 R+ 21:57 0:00 ps auxИз родительского неймспейса виден только процесс, создавший дочерний неймспейс:
user@server:~$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 43 0.0 0.0 7916 828 pts/0 S 21:54 0:00 unshare --fork --pid --mount-proc bashЭто, можно сказать, аналог команды docker ps. С помощью команды lsns (list namespaces) можно перечислить все доступные пространства имен и отобразить информацию о них с точки зрения родительского пространства имен.
alexis@HP840G3:~$ lsns --output-all
NS TYPE PATH NPROCS PID PPID COMMAND UID USER NETNSID NSFS PNS ONS
4026531834 time /proc/408/ns/time 6 408 1 /lib/systemd/systemd 1000 alexis 0 4026531837
4026531835 cgroup /proc/408/ns/cgroup 6 408 1 /lib/systemd/systemd 1000 alexis 0 4026531837
4026531837 user /proc/408/ns/user 6 408 1 /lib/systemd/systemd 1000 alexis 0 0
4026531840 net /proc/408/ns/net 6 408 1 /lib/systemd/systemd 1000 alexis unassigned 0 4026531837
4026532262 ipc /proc/408/ns/ipc 6 408 1 /lib/systemd/systemd 1000 alexis 0 4026531837
4026532274 mnt /proc/408/ns/mnt 6 408 1 /lib/systemd/systemd 1000 alexis 0 4026531837
4026532356 uts /proc/408/ns/uts 6 408 1 /lib/systemd/systemd 1000 alexis 0 4026531837
4026532357 pid /proc/408/ns/pid 6 408 1 /lib/systemd/systemd 1000 alexis 0 4026531837Для выхода из неймспейса используется команда exit, после чего неймспейс удаляется.
Cgroups (control groups)
Мы могли бы создать процесс отдельно от другого процесса с пространствами имен Linux. Но если мы создадим несколько пространств имен, то как мы можем ограничить ресурсы каждого пространства имен, чтобы оно не занимало ресурсы другого пространства имен?
Cgroups определяет лимит процессора и памяти, который может использовать процесс. Cgroups предоставляют следующие возможности:
- Ограничения ресурсов. Вы можете настроить cgroup, чтобы ограничить объем определенного ресурса (CPU, memory, disk I/O, network), который может использовать процесс.
- Расстановка приоритетов. Вы можете контролировать, какую часть ресурса процесс может использовать по сравнению с процессами в другой cgroup при возникновении конкуренции за ресурсы.
- Учет. Ограничения ресурсов отслеживаются на уровне группы и сообщаются ядру.
- Управление. Вы можете изменить статус (заморожен, остановлен или перезапущен) всех процессов в группе с помощью одной команды.
Чтобы создать группу, мы будем использовать cgcreate.
Перед использованием cgcreate нам необходимо установить cgroup-tools.
Ubuntu and Debian
sudo apt-get установить cgroup-toolsCentOS
sudo yum установить libcgroupЗатем мы запускаем следующую команду для создания cgroup:
sudo cgcreate -g memory:my-processПри этом создается папка my-process по пути /sys/fs/cgroup/memory:
$ ls /sys/fs/cgroup/memory/my-process
cgroup.clone_children memory.memsw.failcnt
cgroup.event_control memory.memsw.limit_in_bytes
cgroup.procs memory.memsw.max_usage_in_bytes
memory.failcnt memory.memsw.usage_in_bytes
memory.force_empty memory.move_charge_at_immigrate
memory.kmem.failcnt memory.oom_control
memory.kmem.limit_in_bytes memory.pressure_level
memory.kmem.max_usage_in_bytes memory.soft_limit_in_bytes
memory.kmem.tcp.failcnt memory.stat
memory.kmem.tcp.limit_in_bytes memory.swappiness
memory.kmem.tcp.max_usage_in_bytes memory.usage_in_bytes
memory.kmem.tcp.usage_in_bytes memory.use_hierarchy
memory.kmem.usage_in_bytes notify_on_release
memory.limit_in_bytes tasks
memory.max_usage_in_bytesВ папке мы видим файлы, которые определяют лимиты процесса. Файл, который нас сейчас интересует — это memory.kmem.limit_in_bytes, он будет определять лимит памяти процесса в байтах. Например, это командой мы ограничим лимит по памяти в 50 Mi:
sudo echo 50000000 > /sys/fs/cgroup/memory/my-process/memory.limit_in_bytesЧтобы запустить процесс bash с лимитом в 50 Mi используем:
user@server:~$ sudo cgexec -g memory:my-process bashТеперь мы можем запускать контейнеры изолированно и с ограничениями по ресурсам:
user@server:~$ sudo cgexec -g cpu,memory:my-process unshare -uinpUrf --mount-proc sh -c "/bin/hostname my-process && chroot mktemp -d /bin/sh"
Container runtime
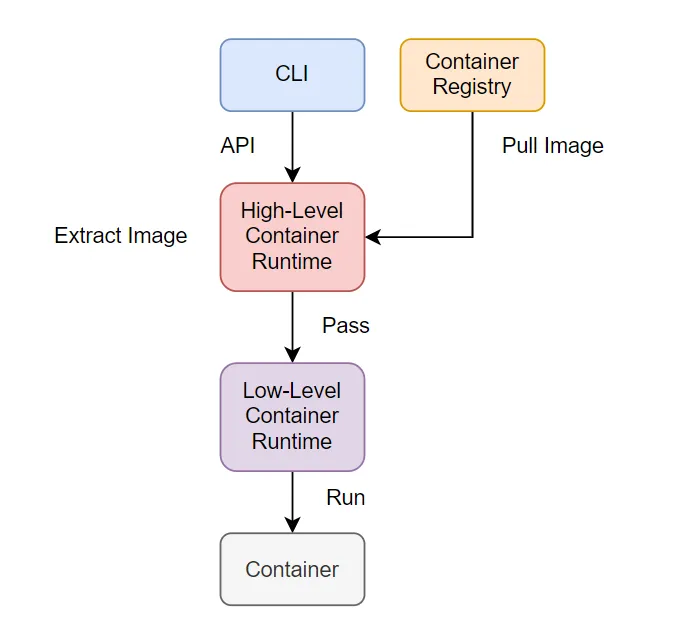
Container Runtime — это инструмент, который управляет всеми запущенными процессами контейнера, включая создание и удаление контейнеров, упаковку и совместное использование контейнеров. Среда выполнения контейнера делится на два типа:
- Низкоуровневая среда выполнения контейнера: основная задача — создание и удаление контейнеров.
- Среда выполнения контейнера высокого уровня: работа с образами для контейнера: скачать, распаковать, и передать его в среду низкого уровня для запуска.
RunC — основной OCI-совместимый инструмент для низкоуровневого управления контейнерами. Его же использует и Docker. Его основные задачи:
- Создать cgroup
- Запустить CLI в cgroup
- Запустить команду unshare, чтобы создать изолированный процесс
- Настроить корневую файловую систему (/root)
- Очистить cgroup после завершения команды.
В runC запуск контейнера выполняется командой:
runc run runc-containerДругие низкоуровневые райнтаймы — crun и Kata.
Райнтаймов высокого уровня гораздо больше, причём они сменяли друг друга, объединялись, прекращали свое существование (например, RKT). Вот небольшое сравнение самых актуальных на данный момент:
| Container Runtime | Поддержка в Kubernetes | Плюсы | Минусы |
| Containerd | Google Kubernetes Engine, IBM Kubernetes Service, Alibaba | Протестировано в огромных масштабах, используется во всех контейнерах Docker. Использует меньше памяти и процессора, чем Docker. Поддерживает Linux и Windows. | Нет сокета Docker API. Не хватает удобных инструментов CLI Docker. |
| CRI-O | Red Hat OpenShift, SUSE Container as a Service | Легкий, все функции, необходимые Kubernetes, и не более того. UNIX-подобное разделение задач (клиент, реестр, сборка). | В основном используется на платформах Red Hat. Непростая установка в операционных системах, отличных от Red Hat. Поддерживается только в Windows Server 2019 и более поздних версиях. |
| Kata Containers | OpenStack | Обеспечивает полную виртуализацию на основе QEMU. Улучшенная безопасность. Интегрируется с Docker, CRI-O, Containerd и Firecracker. Поддерживает ARM, x86_64, AMD64. | Более высокое использование ресурсов. Не подходит для случаев использования легких контейнеров. |
| AWS Firecracker | All AWS services | Доступен через прямой API или контейнер. Тесный доступ к ядру с помощью seccomp Jaler. | Новый проект, менее зрелый, чем другие среды выполнения. Требуется больше действий вручную, опыт разработчиков все еще меняется. |
Теперь попробуем разобраться, как все рантаймы и компоненты между собой взаимодействует. Для этого определены стандарты и интерфейсы.
- Open Container Initiative (OCI): набор стандартов для контейнеров, описывающих формат образа, среду выполнения и распространение.
- Container Runtime Interface (CRI) в Kubernetes: API, который позволяет использовать различные среды выполнения контейнеров в Kubernetes.
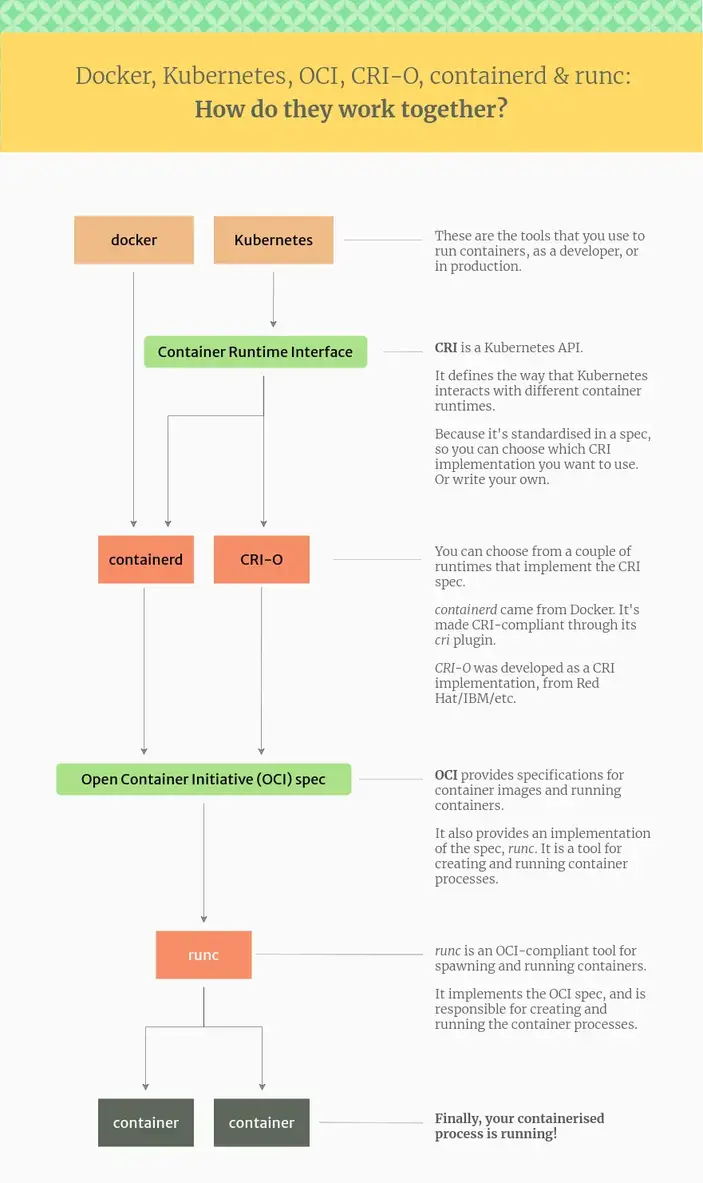
Из схемы выше становится понятно, что Docker сам по себе не является рантаймом, но но использует OCI- и CRI-совместимые рантаймы для работы. А Kubernetes может работать с различными райнтаймами, через CRI. Существует и cri-dockerd реализация от Mirantis, но она не часто используется.
Как работает Docker?
Ниже приведены инструменты, которые Docker использует для запуска контейнеров:
- Среда выполнения контейнера низкого уровня. runc — это низкоуровневая среда выполнения контейнера. Он использует встроенные функции Linux для создания и запуска контейнеров. Он соответствует стандарту OCI и включает libcontainer, библиотеку Go для создания контейнеров.
- Высокоуровневая среда выполнения контейнера. Containerd находится над низкоуровневой средой выполнения и добавляет множество функций, таких как передача образов, хранение и работа в сети. Он также полностью поддерживает спецификацию OCI.
- Демон Docker. dockerd — это процесс-демон, который предоставляет стандартный API и взаимодействует со средой выполнения контейнера.
- Высший уровень. Инструмент Docker CLI. Наконец, docker-cli дает вам возможность взаимодействовать с демоном Docker с помощью команд docker ... Это позволяет вам управлять контейнерами без необходимости разбираться в нижних уровнях.
Итак, на самом деле, когда вы запускаете контейнер с помощью Docker, вы фактически запускаете его через демон Docker, который вызывает контейнер, который затем использует runc.
Контейнеры в Kubernetes
Интерфейс среды выполнения контейнера (CRI) — это интерфейс плагина, который позволяет kubelet — агенту, работающему на каждом узле кластера Kubernetes, — использовать более одного типа среды выполнения контейнера. Kubelet взаимодействует со средой выполнения контейнера (или оболочкой CRI для среды выполнения) через сокеты Unix с использованием инфраструктуры gRPC, где kubelet выступает в роли клиента, а оболочка CRI — в качестве сервера. CRI состоит из буферов протоколов и gRPC API , а также библиотек с дополнительными спецификациями и инструментами, которые находятся в стадии активной разработки.
Ранее Kubernetes поддерживал Docker Engine, чтобы запускать контейнеры, поэтому во многих мануалах по настройке кластера вы можете увидеть шаг про установку docker, но больше это так не работает. Сам по себе Docker не поддерживает CRI, поэтому был разработан слой совместимости, который назывался dockershim. Но начиная с Kubernetes 1.24 компонент dockershim был полностью удален, поэтому теперь необходимо пользоваться containerd, CRI-O или другими рантаймами.
Важно! Это не означает, что Kubernetes не может запускать контейнеры в формате Docker. И containerd, и CRI-O могут запускать образы в формате Docker и OCI в Kubernetes; они могут сделать это без использования команды docker или демона Docker.
Конфигурация containerd содержится в /etc/containerd/config.toml, а Unix-сокет для взаимодействия /run/containerd/containerd.sock. В файле конфигурации можно настроить взаимодействие runC с cgroups драйвером. Там же включается CRI интеграция.
При инициализации кластера через утилиту kubeadm можно передавать структуру KubeletConfiguration. Эта конфигурация KubeletConfiguration может включать поле cgroupDriver, которое управляет драйвером cgroup kubelet. В версии кубера 1.22 и более поздних версиях, если пользователь не задает поле cgroupDriver в разделе KubeletConfiguration, kubeadm по умолчанию устанавливает для него значение systemd:
# kubeadm-config.yaml
kind: ClusterConfiguration
apiVersion: kubeadm.k8s.io/v1beta3
kubernetesVersion: v1.21.0
---
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
cgroupDriver: systemdПрименить манифест можно так:
kubeadm init --config kubeadm-config.yamlKubeadm использует одну и ту же конфигурацию KubeletConfiguration для всех узлов кластера. KubeletConfiguration хранится в объекте ConfigMap в пространстве имен kube-system. Выполнение подкоманд init, join и update приведет к тому, что kubeadm запишет KubeletConfiguration в виде файла в /var/lib/kubelet/config.yaml и передаст его локальному узлу kubelet.
CRI-O по умолчанию использует драйвер cgroup systemd, который, скорее всего, вас устроит. Чтобы переключиться на драйвер cgroup cgroupfs, отредактируйте /etc/crio/crio.conf.